
Apache Fury (incubating) is a multi-language serialization framework powered by JIT dynamic compilation and zero copy. It implements multi-language SDKs: Java, Python, Golang, JavaScript, Rust, C++. It provides automatic multi-language objects serialization features, and 170x speedup compared to JDK serialization.
The GitHub address of fury repository is: https://github.com/apache/fury

Background
Serialization is a basic component of system communication, and widely used in big data, AI framework, cloud native and other distributed systems. Data transfer between processes, languages, nodes, or object persistence, state read-write and copy, all need serialization. The performance and ease-of-use of serialization affects runtime and development efficiency of the system.
Static serialization frameworks like Protobuf or FlatBuffers cannot be used for cross-language application development directly, because they don't support shared reference and polymorphism, and also need to generate code ahead.
Dynamic serialization frameworks such as JDK serialization, Kryo, Fst, Hessian, Pickle provide ease-of-use and dynamics, but don't support cross-language and suffer significant performance issues, which is unsuitable for high throughput, low latency, and large-scale data transfer scenarios.
Therefore, we developed a new multi-language serialization framework Apache Fury, which is open-sourced on https://github.com/apache/fury. Through highly optimized serialization primitives, JIT dynamic compilation and zero-copy technologies, Fury is both fast and easy-to-use. It can cross-language serialize any object automatically and provides ultimate performance at the same time.
What is Apache Fury?
Apache Fury is a multi-language serialization framework powered by JIT dynamic compilation and zero copy, providing blazing fast speed and ease of use:
- Multiple languages: Java, Python, C++, Golang, JavaScript, Rust. Other languages can be added easily.
- Highly optimized serialization primitives.
- Zero-copy: Support out-of-band serialization and off-heap read/write.
- High performance: Use JIT to generate serialization code at runtime in an async multithreaded way, which can optimize methods inlining, code cache, dead code elimination, hash lookup, meta writing and memory read/write.
- Multi protocols: Provide flexibility and ease of use of dynamic serialization, as well as the cross-language of static serialization.
- Java Serialization:
- Drop-in replaces JDK, Kryo, and Hessian. No need to modify user code, but providing 170x speed up at most, which can improve efficiency of rpc, data transfer and object persistence significantly.
- 100% JDK compatible, support JDK custom serialization methods
writeObject,readObject,writeReplace,readResolve,readObjectNoDatanatively.
- Cross-language object graph:
- Cross-language serialize any objects automatically, no need for IDL, schema compilation, and object/protocol conversion.
- Cross-language serialize shared/circular reference, no data duplication or recursion error.
- Support object polymorphism, multiple children type objects can be serialized simultaneously.
- Row format
- A cache-friendly binary random-access format, supports skipping deserialization and lazy deserialization, efficient for high-performance computing and large-scale data transfer.
- Support automatic conversion to Apache Arrow.
- Java Serialization:
Core Serialization Capabilities
Although different scenarios require different serialization protocols, the underlying operations of serialization are similar.
Therefore, Fury defines and implements a set of basic serialization capabilities, which can be used for quickly building new multi-language serialization protocols and get speedup by JIT acceleration and other optimizations.
At the same time, performance optimization for a protocol on the primitives can also benefit all other protocols.
Serialization Primitives
Common serialization operations contains:
- Bitmap operations
- Number encoding and decoding
- Compression for int and long
- String creation and copy
- String encoding: ASCII, UTF8, UTF16
- Memory copy
- Array copy and compression
- Meta encoding, compression, and cache
Fury use SIMD and other advanced language features to make basic operations extremely fast in every languages.
Zero-copy Serialization
Large-scale data transfer often has multiple binary buffers in an object graph. Some serialization frameworks will write the binaries into an intermediate buffer and introduce multiple time-consuming memory copies. Fury implemented an out-of-band serialization protocol inspired by pickle5, Ray and Apache Arrow, which can capture all binary buffers in an object graph to avoid intermediate copies of these buffers.
The following figure shows the serialization process of zero-copy:
Currently, Fury supports the following types of zero-copy:
- Java: all basic types of arrays,
ByteBuffer,ArrowRecordBatch, andVectorSchemaRoot - Python: all arrays of the array module, numpy arrays,
pyarrow.Table, andpyarrow.RecordBatch - Golang: byte slice
You can also add the new zero copy type based on the Fury interface.
JIT dynamic compilation acceleration
Custom type objects usually contain lots of type information, Fury used this information to generate efficient serialization code at runtime, which can push lots of runtime operations into the dynamic compilation stage. By inlining more methods, better code cache, reducing virtual method calls, conditional branches, hash lookup, metadata writes, and memory reads/writes, the serialization performance is greatly accelerated.
For Java, Fury implements a runtime codegen framework and defines an operator expression IR. Then fury can perform type inference based on the generic type information of the object at runtime to build an expression tree that describes the logic of serialized code.
The codegen framework will generate efficient Java code from the expression tree, then pass to Janino to compile it into bytecode, and load it into the user's ClassLoader or the ClassLoader created by Fury, and finally compile it into efficient assembly code through Java JIT.
Since JVM JIT skips Big method compilation and inlining, Fury also implements an optimizer to split big methods into small methods recursively, thus ensuring that all code can be compiled and inlined.
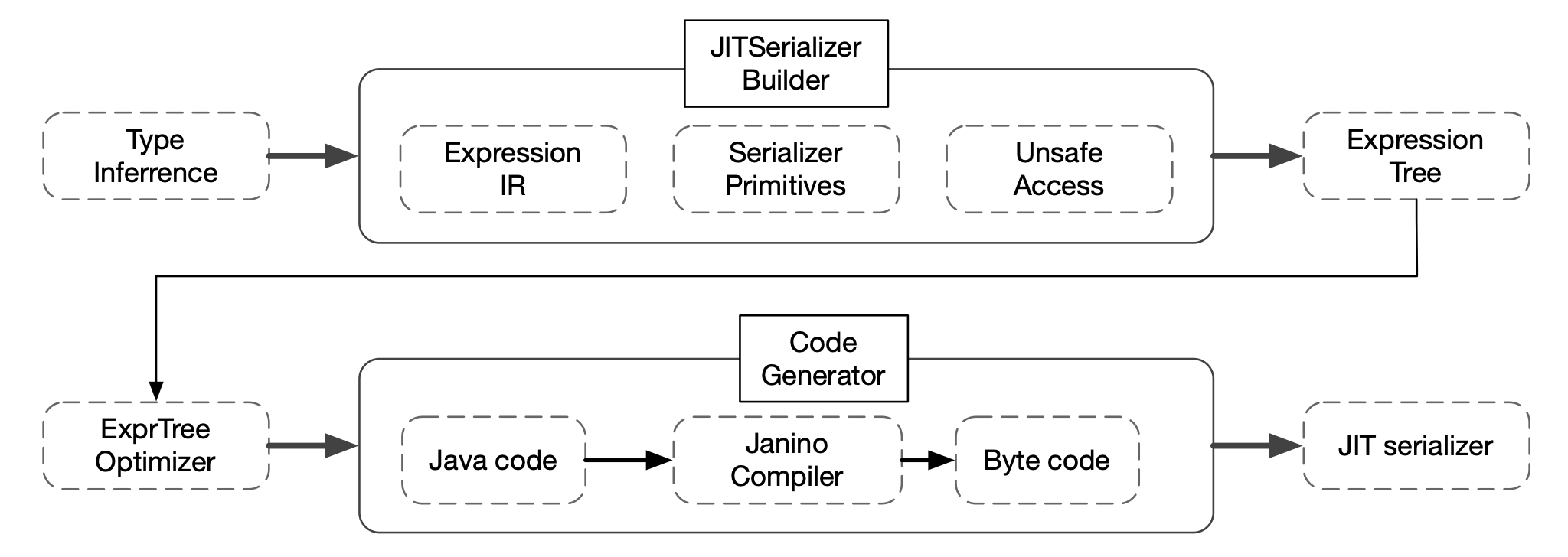
Fury also supports asynchronous multithreaded compilation by running the codegen tasks in a thread pool, and using interpretation mode until JIT finishes to ensure no serialization burrs. Users can skip warm up serialization of objects.
Python and JavaScript codegen are similar. Generating source code is easier for development and troubleshooting problems.
Since serialization will manipulate objects extensively in each programming language, and the language does not expose the low-level API of the memory model, native methods call has a large cost too, so we cannot use LLVM to build a unified serializer JIT framework. Instead, we implemented a codegen framework for every language separately.
Static code generation
Although JIT compilation can greatly improve serialization efficiency and generate better serialization code based on the statistical distribution of data at runtime, languages like C++ do not support reflection, have no virtual machines, and no low-level API for memory models. We cannot generate serialization code dynamically for such languages through JIT.
In such scenarios, Fury is implementing an AOT codegen framework, which generates the serialized code statically according to the object schema, and objects can be serialized automatically using the generated serializer. For Rust, Rust macro is used to generate code statically.
Cache optimization
When serializing a custom type, fury will reorder fields to ensure that fields of the same type are serialized in order. This can hit more data cache and CPU instruction cache.
The basic type fields are written in descending order by byte size. In this way, if the initial addresses are aligned, subsequent read and write operations will occur at the position where the memory addresses are aligned, making CPU execution more efficient.
Multi-protocol Design and Implementation
Based on the multi-language serialization features provided by Fury core, we have built three serialization protocols for different scenarios:
- Java serialization: Suitable for pure Java serialization scenarios and provides up to 170x speed up;
- Cross-language object graph serialization: Suitable for application-oriented multi-language programming and high-performance cross-language serialization;
- Row-format serialization: Suitable for distributed computing engines such as Apache Spark, Apache Flink, Apache Doris, Velox, and features frameworks.
In the future, we will add new protocols for other core scenarios. Users can also build their own protocols based on Fury's serialization framework.
Java serialization
Java is widely used in big data, cloud native, microservices, and enterprise applications. Therefore, Fury made lots of optimizations for Java serialization, which reduces system latency and server costs a lot, and improves throughput significantly. Our implementation has the following highlights:
- Blazing fast performance: Based on Java types, JIT compilation and Unsafe low-level operations, Fury is 170x faster than JDK, and 50~110x faster than Kryo/Hessian at most.
- 100% JDK serialization API compatibility : Supports all JDK custom serialization methods
writeObject,readObject,writeReplace,readResolve,readObjectNoDatanatively to ensure the serialization correctness in any scenario. Kryo and Hessian have some correctness issues in these scenarios. - Type compatibility: When the deserialization and serialization class schema are inconsistent, it can still deserialize correctly. It supports application upgrade and deployment, add/delete fields independently. Fury type-compatible mode is implemented with no performance loss compared to type-consistent mode.
- Metadata sharing : share metadata(class name, field name&type, etc.) across multiple serializations under a context (TCP connection), meta will be sent to the peer only for the first serialization, the peer can reconstruct the same deserializer based on this information. Subsequent serialization will skip transferring metadata, which can reduce network traffic, and support type compatibility automatically.
- Zero-copy support: supports out-of-band zero copy and off-heap memory read and write.
Cross-language object graph serialization
Fury cross-language object graph serialization is primarily used for scenarios that require higher dynamics and ease-of-use.
Although frameworks like Protobuf or FlatBuffers support cross-language serialization, they still have limitations:
- They require pre-defined IDLs and generate code statically ahead, lacking sufficient dynamics and flexibility;
- The generated classes don't conform to object-oriented design and it's impossible to add behavior to classes, which make them unsuitable for use as domain objects in cross-language application development.
- They don't support polymorphism. Object-oriented programming uses interfaces to invoke subclass methods, but this pattern isn't supported well in those frameworks. Although FlatBuffers offers
Union, and Protobuf providesOneOf/Any, those API require check object type during serialization and deserialization, which isn't polymorphic. - They don't support circular references and shared references. Users need to define a set of IDLs for domain objects and implement reference resolution by themselves, as well as writing code to convert between domain objects and protocol objects in each language. If the object graph depth is deep, more code needs to be written.
Due to the above limitations, Fury implemented a cross-language object graph serialization protocol that:
- Automatically serializes any object across multiple languages: By defining classes in the serialization and deserialization peer, objects in one language can be automatically serialized into objects in another language without creating IDL files, compiling schema to generate code, or writing conversion code.
- Automatically serializes shared and circular references across multiple languages.
- Supports object type polymorphism, consistent with the object-oriented programming paradigm, and multiple subtypes can be automatically deserialized without manual intervention.
- Out-of-band zero-copy is also supported in this protocol.
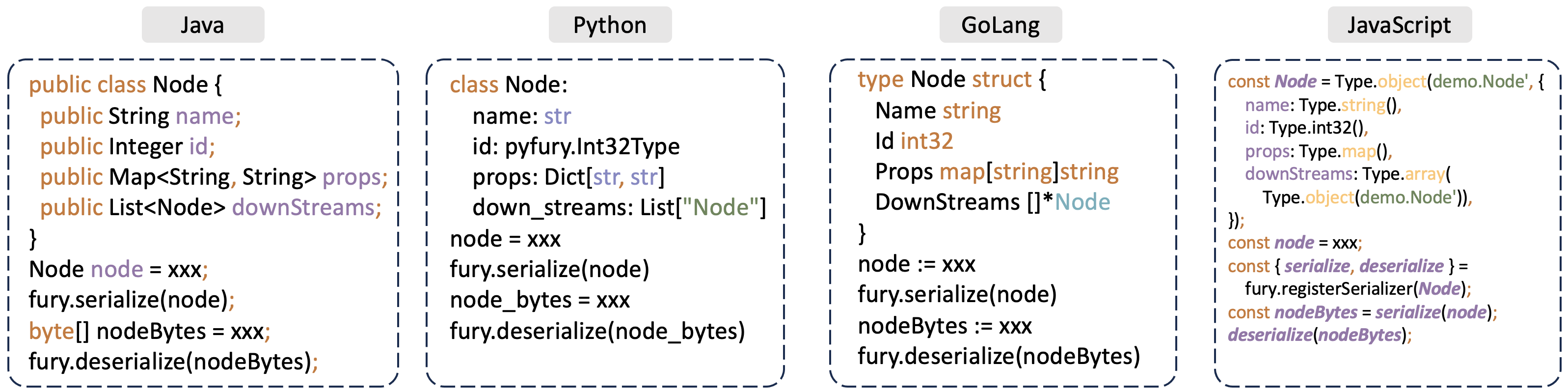
Example of Automatic Cross-Language Serialization:
Row-format
For high-performance computing and large-scale data transfer scenarios, data serialization and transfer are often the performance bottlenecks of the system. If users only need to read part of the data or filter data based on some field of an object, deserializing the entire data will result in unnecessary overhead. Therefore, Fury provides a binary data structure for direct reading and writing on binary data to avoid serialization.
Apache Arrow is a standardized columnar storage format that supports binary read and write. However, columnar format is not suitable for all scenarios. Data in online and streaming computing are naturally stored row by row, and row is also used in columnar computing engines when involving data updates, Hash/Join/Aggregation operations.
However, there is no standardized implementation for row format. Computing engines such as Spark/Flink/Doris/Velox all defined their row format, which doesn't support cross-language and can only be used internally by themselves. FlatBuffers does support lazy deserialization, but it requires static compilation of schema IDL and management of offset, which is impossible for complex scenarios.
Therefore, Fury implemented a binary row format inspired by Spark Tungsten and Apache Arrow format, which allows random access and partial deserialization. Currently, Java/Python/C++ versions have been implemented, allowing direct reading and writing on binary data to avoid all serialization overhead, and can convert to arrow format automatically.
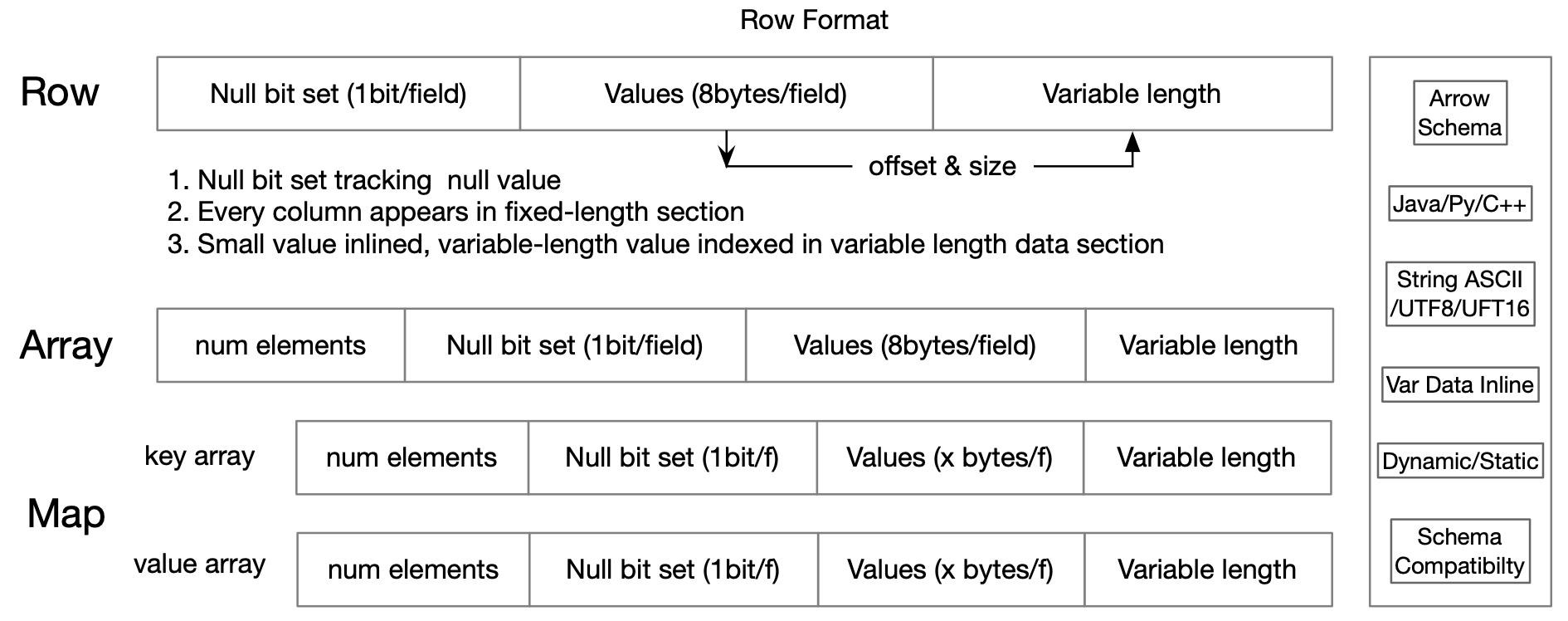
This format is densely stored, byte aligned and cache-friendly, which enables faster read and write operations. By avoiding deserialization, it reduces Java GC pressure and Python overhead. Based on Python's dynamics, Fury's data structure implements special methods such as getattr, getitem, slice, etc., ensuring behavior consistency with Python dataclass, list, object, and users have no perception of this.
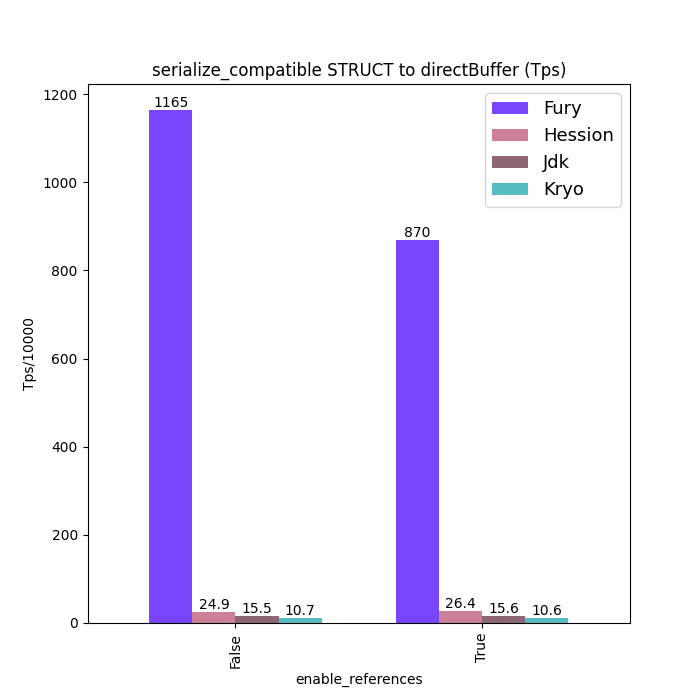
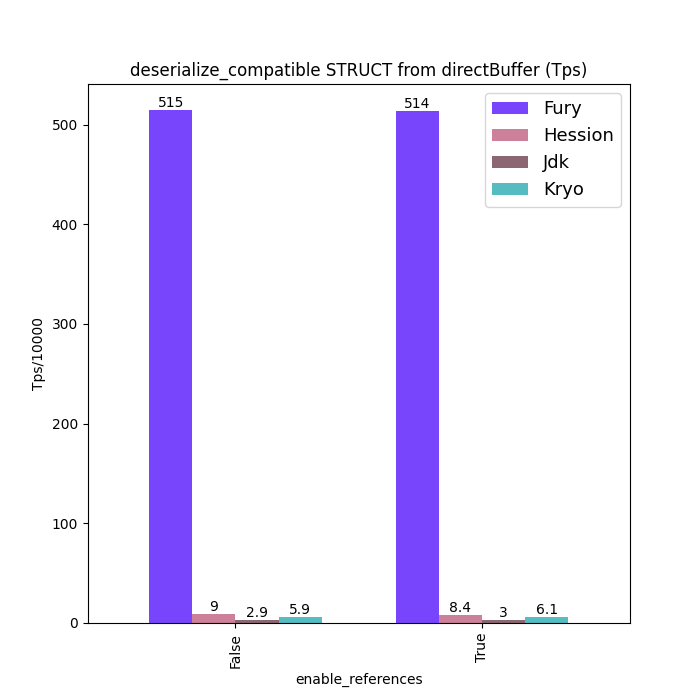
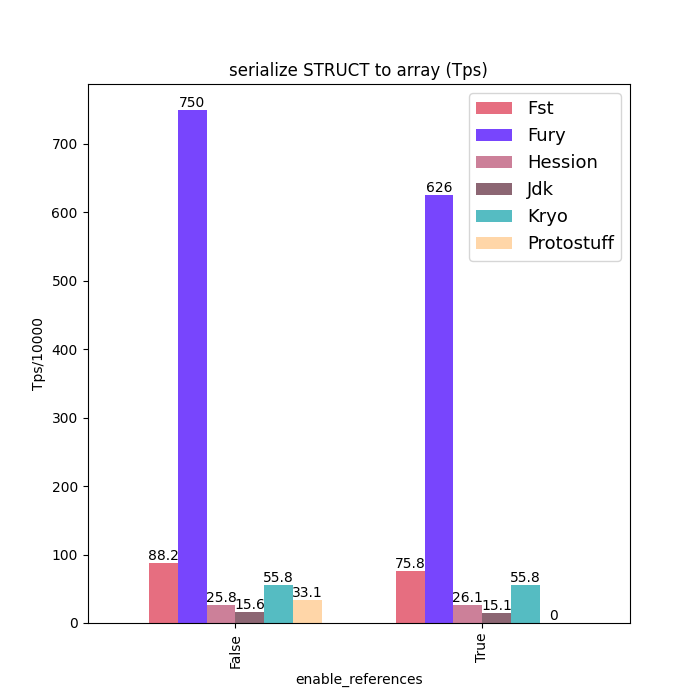
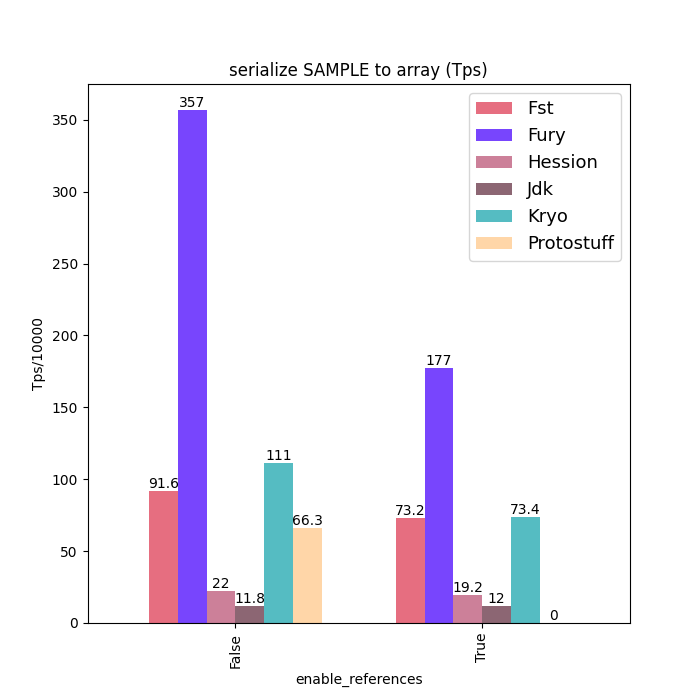
Performance Comparison
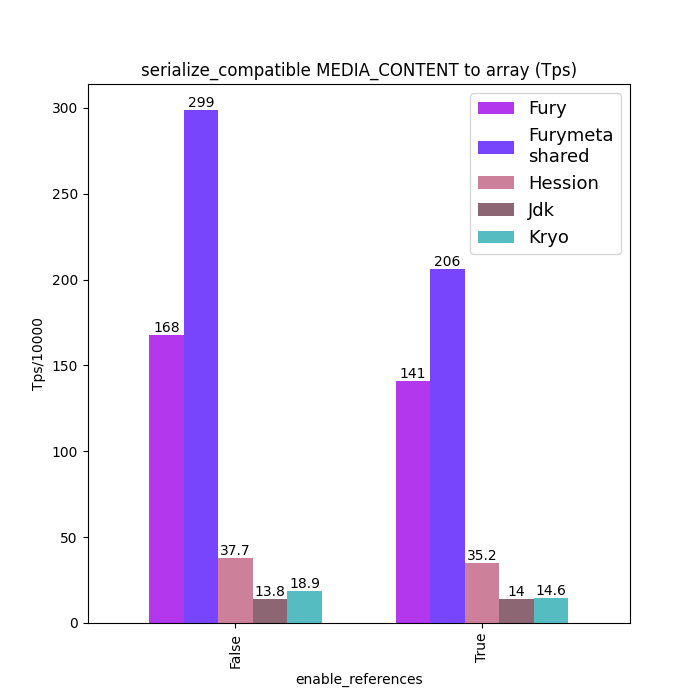
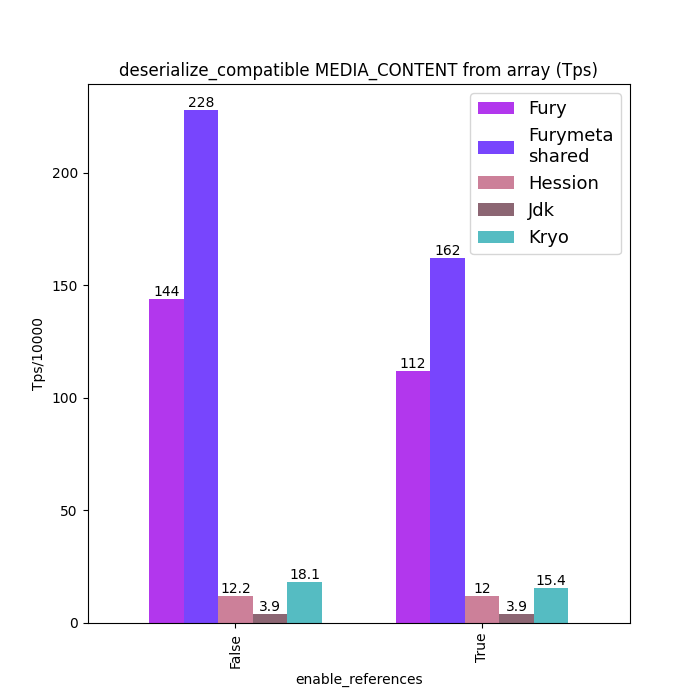
Here are some Java serialization performance data, where charts with "compatible" in the title are performance data under type compatible mode: Support type forward vs. Backward compatibility. Charts without "compatible" in the title are performance data without type compatibility: class schema must be same between serialization and deserialization.
For fairness, Fury disabled the zero-copy feature for all tests.
Roadmap
- Meta compression, auto meta sharing and cross-language schema compatibility.
- AOT Framework for C++ and Golang to generate code statically.
- Object graph serialization support for C++ and Rust
- Row format support for Golang, Rust, and NodeJS
- Protobuf compatibility support
- Protocols for features and knowledge graph serialization
- Continuously improve our serialization infrastructure for any new protocols
Join us
We are committed to building Apache Fury into an open and neutral community project that pursues passion and innovation. The development and discussion are open-sourced and transparent in the community. Any form of participation is welcome, including but not limited to questions, code contributions, technical discussions, etc. We are looking forward to receiving your ideas and feedback, participating in the project together, pushing the project forward and creating a better serialization framework.
The GitHub address of the fury repository is: https://github.com/apache/fury
Official website: https://fury.apache.org
All issues, PR, and Discussion are welcome.